library(tidyverse)信頼区間の意味がわかりやすいシミュレーション
パッケージの読み込み
設定
- 100人の研究者がいる
- 各研究者がそれぞれデータをとる。N=500の調査を行う
- データは平均0.5、標準偏差0.1の正規分布に従うと仮定
set.seed(1)
data <-
tibble(
# 100人の研究者がいる
researcher_ID = 1:100,
# 各研究者がそれぞれデータをとる。N=500の調査を行う。
data = map(researcher_ID, \(researcher_ID) rnorm(500, 0.5, 0.1))
)
data# A tibble: 100 × 2
researcher_ID data
<int> <list>
1 1 <dbl [500]>
2 2 <dbl [500]>
3 3 <dbl [500]>
4 4 <dbl [500]>
5 5 <dbl [500]>
6 6 <dbl [500]>
7 7 <dbl [500]>
8 8 <dbl [500]>
9 9 <dbl [500]>
10 10 <dbl [500]>
# ℹ 90 more rowsデータから信頼区間を計算
- 各研究者のデータの平均値、標準誤差、信頼区間を計算
- 信頼区間が真値(0.5)を含むかどうかを判定
data2 <-
data |>
# 各研究者のデータの平均値、標準誤差、信頼区間を計算
mutate(
mean = map_dbl(data, \(data) mean(data)),
se = map_dbl(data, \(data) sd(data) / sqrt(length(data))),
lower = mean - 1.96 * se,
upper = mean + 1.96 * se
) |>
# 信頼区間が0.5を含むかどうかを判定
mutate(
flg = case_when(
0.5 < lower | upper < 0.5 ~ 'Error',
.default = 'Not Error'
)
)
data2# A tibble: 100 × 7
researcher_ID data mean se lower upper flg
<int> <list> <dbl> <dbl> <dbl> <dbl> <chr>
1 1 <dbl [500]> 0.502 0.00453 0.493 0.511 Not Error
2 2 <dbl [500]> 0.495 0.00473 0.486 0.505 Not Error
3 3 <dbl [500]> 0.500 0.00452 0.491 0.509 Not Error
4 4 <dbl [500]> 0.497 0.00479 0.488 0.506 Not Error
5 5 <dbl [500]> 0.501 0.00464 0.492 0.510 Not Error
6 6 <dbl [500]> 0.502 0.00459 0.493 0.511 Not Error
7 7 <dbl [500]> 0.509 0.00476 0.500 0.518 Not Error
8 8 <dbl [500]> 0.494 0.00451 0.486 0.503 Not Error
9 9 <dbl [500]> 0.499 0.00440 0.491 0.508 Not Error
10 10 <dbl [500]> 0.497 0.00446 0.488 0.505 Not Error
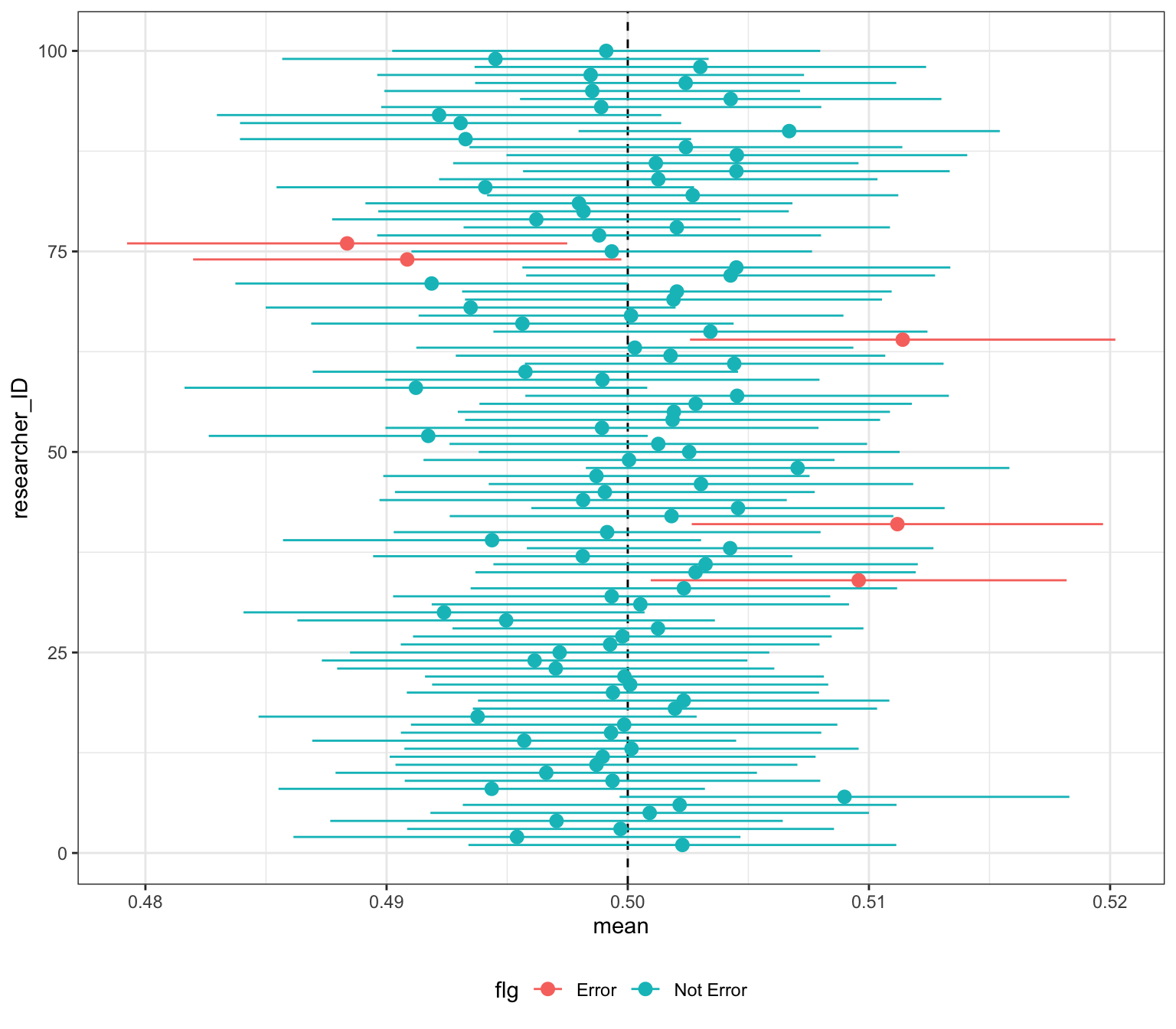
# ℹ 90 more rows各研究者の信頼区間を図示
- 点推定値は0.5に近いのもあれば、遠いのもある
- 信頼区間が真値(0.5)を含まない、「不運」な研究者は、5人 / 100人(5%)
- 95%の研究者は真の値を拾える、という意味
- 実際には自分が「不運」な研究者かもしれないし、信頼区間の端ギリギリで真値を拾っているだけかもしれない
# 図示
data2 |>
ggplot(aes(mean, researcher_ID, xmin = lower, xmax = upper, color = flg))+
geom_vline(xintercept = 0.5, linetype = 'dashed')+
geom_pointrange()+
theme_bw()+
theme(legend.position = 'bottom')